

Il Mito della Viralità
Come un miliardo di eventi Twitter ha demolito tutto quello che credevamo di sapere sulla diffusione dei contenuti online
Il Video da Un Milione di Dollari
12 febbraio 2012. Dollar Shave Club carica su YouTube un video da un milione di dollari girato in un giorno. Michael Dubin, fondatore dell’azienda, cammina in un magazzino spiegando con deadpan delivery perché spendere venti dollari per un rasoio è assurdo. In 48 ore: 12.000 ordini. In quattro anni: acquisizione da parte di Unilever per un miliardo di dollari.
Chiamatelo virale se volete. Ma state mentendo a voi stessi.
Quello che è successo quel giorno non ha nulla a che fare con il contagio person-to-person che immaginiamo quando pensiamo alla viralità. Non è stata una cascata virale attraverso generazioni di condivisioni. È stato broadcast precision engineering amplificato algoritmicamente. La differenza non è semantica. È strutturale. Ed è esattamente quello che Duncan Watts e il suo team hanno dimostrato analizzando un miliardo di eventi di diffusione su Twitter.
La scoperta è disturbante nella sua semplicità: la viralità strutturale — quella vera, quella delle cascate multi-generazionali dove ogni persona ne infetta altre due, che ne infettano altre quattro, in progressione esponenziale — è rara. Estremamente rara. Nella stragrande maggioranza dei casi, la popolarità è determinata dalla dimensione del broadcast più grande, non dalla profondità della diffusione virale.
Tradotto: non è quanto in profondità il tuo contenuto penetra nella rete sociale. È quanto grande è il megafono algoritmico che le piattaforme decidono di darti.
Un Miliardo di Eventi Non Mentono
Il team di Watts ha analizzato un dataset che fa impallidire qualsiasi ricerca precedente sulla viralità: un miliardo di eventi di diffusione su Twitter, includendo propagazione di notizie, video, immagini e petizioni. I risultati contraddicono frontalmente l’immaginario collettivo su come le cose diventano popolari online.
Primo: il 93% dei tweet non riceve nemmeno un retweet. Zero. Il 5% ne riceve uno. Lo 0,9% ne riceve due. La distribuzione segue una power law brutale che lascia la maggior parte dei contenuti nell’oscurità totale mentre una minuscola frazione esplode. Ma anche quando esplodono, il meccanismo non è quello che crediamo.
Secondo: quando Watts e colleghi hanno misurato la “structural virality” — interpolando tra contenuti che crescono tramite singoli grandi broadcast e contenuti che crescono attraverso multiple generazioni con ogni individuo responsabile solo di una frazione dell’adozione totale — hanno scoperto che la structural virality è tipicamente bassa. E rimane bassa indipendentemente dalla dimensione dell’evento virale.
Terzo: la correlazione tra popolarità e structural virality è sorprendentemente bassa. Sapere quanto è popolare un contenuto ti dice pochissimo su come si è diffuso. I contenuti massivamente popolari si diffondono quasi sempre attraverso grandi broadcast, non attraverso catene virali profonde.
Questo smantella l’intero framework concettuale con cui pensiamo alla diffusione online. La metafora epidemiologica — virus che si diffonde di persona in persona, contagio esponenziale, paziente zero — è fuorviante. Quello che accade davvero è più simile alla televisione che all’influenza. Grandi emittenti (gli hub della rete, gli account con milioni di follower, gli algoritmi di raccomandazione delle piattaforme) decidono cosa milioni di persone vedranno simultaneamente.
Barabási e l’Aristocrazia Algoritmica
Per capire perché la viralità funziona così, bisogna capire l’architettura delle reti sociali. Albert-László Barabási ha passato decenni a studiare network reali — Internet, reti di collaborazione scientifica, reti metaboliche cellulari — scoprendo che quasi tutti seguono una struttura scale-free governata da due principi: growth e preferential attachment.
Growth significa che il numero di nodi aumenta nel tempo. Nuovi utenti si uniscono alla piattaforma, nuovi creator iniziano a postare, la rete si espande continuamente. Ma è il preferential attachment che crea la vera asimmetria di potere: quando un nuovo nodo entra nella rete, tende a connettersi ai nodi già ben connessi. I ricchi diventano più ricchi. Gli hub accumulano collegamenti a un tasso sproporzionato rispetto ai nodi ordinari.
Pensateci in termini di network sociali. Sei nuovo su Instagram. Chi segui? Non account casuali. Segui celebrità, influencer, account già popolari. Questo comportamento — ripetuto miliardi di volte — crea una distribuzione power-law dove pochi account hanno milioni di follower mentre la maggioranza ne ha decine o centinaia. La struttura risultante non è democratica. È profondamente aristocratica.
E qui entra in gioco la dinamica cruciale per la diffusione: in un network scale-free, l’epidemic threshold è sempre zero. In parole povere, qualsiasi tasso di infezione, per quanto basso, può teoricamente generare un’epidemia se colpisce gli hub giusti. Ma il corollario è altrettanto importante: senza colpire gli hub, anche contenuti con alto potenziale di condivisione rimangono marginali.
Gli algoritmi di raccomandazione non sono neutrali osservatori di questo processo. Sono attivi selettori di quali hub amplificare e quando. TikTok decide se il tuo video raggiunge 300 persone o 3 milioni. Instagram determina se finisci nell’Explore page di 100.000 utenti o di zero. YouTube sceglie se il tuo contenuto viene raccomandato dopo video con milioni di visualizzazioni o seppellito nell’irrilevanza.
La viralità, quindi, non è proprietà intrinseca del contenuto. È concessione temporanea di accesso agli hub del network. È governance algoritmica travestita da meritocrazia virale.
STEPPS: Cosa Funziona Davvero
Jonah Berger, marketing professor alla Wharton School, ha passato oltre un decennio a studiare perché certe cose diventano popolari e altre no. Ha analizzato quasi 7.000 pezzi di contenuto online, 6.000 consumatori su più di 1.200 prodotti e brand, articoli del New York Times più inoltrati via email, nomi di bambini, mode culturali. Il risultato è un framework chiamato STEPPS che smonta alcuni miti sulla viralità.
Primo mito demolito: i contenuti interessanti ottengono più passaparola di quelli noiosi. Falso. Nella ricerca di Berger, prodotti “noiosi” come Cheerios ottengono tanto word-of-mouth quanto Disney World. La differenza non è nell’interesse intrinseco ma nei trigger — quanto frequentemente le persone incontrano stimoli che li fanno pensare al prodotto. Top-of-mind means tip-of-tongue. Se ci pensi spesso, ne parli spesso.
Secondo: solo il 7% del word-of-mouth accade online. Il restante 93% avviene in conversazioni face-to-face. I social media non sono il veicolo della viralità ma l’amplificatore di dinamiche che esistono già offline. Questo ribalta la prospettiva: invece di ottimizzare per l’algoritmo, bisogna ottimizzare per generare conversazioni nella vita reale che poi tracimano online.
Il framework STEPPS identifica sei principi che rendono le cose contagiose: Social Currency (condividiamo cose che ci fanno apparire bene), Triggers (top-of-mind significa tip-of-tongue), Emotion (quando ci importa, condividiamo), Public (costruito per essere visto, costruito per crescere), Practical Value (notizie che le persone possono usare), Stories (informazione viaggia sotto le vesti di chiacchiere apparentemente oziose).
Prendiamo l’Emotion. Non tutte le emozioni sono uguali. Berger ha scoperto che emozioni ad alto arousal — meraviglia, eccitazione, umorismo, rabbia, ansia — evocano azione. Emozioni a basso arousal — contentezza, tristezza — portano le persone a non fare nulla. Questo spiega perché contenuti che generano rabbia (outrage marketing) o meraviglia (awe-inspiring content) dominano i social. Non è manipolazione cinica, è meccanica emotiva della condivisione.
Ma c’è un livello più profondo, più oscuro. Nel 2014, Adam Kramer di Facebook e colleghi di Cornell hanno pubblicato quello che è diventato l’esperimento più controverso nella storia dei social media: hanno manipolato i News Feed di 689.003 utenti per una settimana, riducendo l’esposizione a contenuti emotivamente positivi per metà del campione e negativi per l’altra metà.
Risultato: quando le espressioni positive venivano ridotte, le persone producevano meno post positivi e più negativi. Quando le espressioni negative venivano ridotte, accadeva l’opposto. Emotional contagion funziona. Le piattaforme possono alterare lo stato emotivo di centinaia di migliaia di persone modificando cosa vedono nei loro feed. E lo fanno senza il loro consenso o consapevolezza.
L’outrage che seguì la pubblicazione dello studio non riguardava tanto la manipolazione in sé — che Facebook effettua costantemente attraverso il suo algoritmo — ma il fatto di averla resa esplicita, di aver tolto il velo sull’illusione che il News Feed mostri semplicemente “quello che i tuoi amici stanno condividendo”. Il News Feed è un ambiente emotivo ingegnerizzato. Ogni piattaforma lo è.
Anatomia di un Algoritmo: TikTok e il Collapse del Tempo
Se vuoi capire come funziona davvero la diffusione algoritmica nel 2025, devi capire TikTok. Non perché sia l’unica piattaforma importante ma perché ha perfezionato il meccanismo di raccomandazione fino a renderlo quasi puro. Instagram e YouTube stanno ancora migrando verso questo modello. TikTok ci è nato.
Il For You Page di TikTok non si basa su chi segui. Si basa su cosa guardi, quanto a lungo, quando esci, cosa skippa, cosa rivedi, cosa condividi. La piattaforma traccia watch time con precisione al millisecondo. Se guardi i primi 3 secondi di un video e esci, l’algoritmo lo nota. Se lo guardi fino alla fine, lo nota. Se lo guardi due volte, lo nota eccome.
Uno studio dell’Università di Washington che ha analizzato 9,2 milioni di raccomandazioni video da 347 utenti TikTok ha scoperto che nei primi 1.000 video mostrati agli utenti, un terzo-metà erano basati sulle predizioni di TikTok su cosa piace all’utente. Nei primi 120 giorni di utilizzo, il tempo medio giornaliero sulla piattaforma è aumentato da 29 minuti a 50 minuti. Ma gli utenti guardano solo il 55% dei video fino alla fine.
Cosa significa? Che l’algoritmo sta costantemente testando, raffinando, ottimizzando. Ogni video che non finisci di guardare è un segnale negativo. Ogni video che rivedi è un segnale fortemente positivo. L’algoritmo impara non solo cosa ti piace ma con quale intensità emotiva reagisci ai contenuti.
Il follower count non è un fattore diretto di ranking. TikTok te lo dice esplicitamente. Questo è radicalmente diverso da come funzionavano i social precedenti. Su Instagram pre-algoritmo, se avevi 10.000 follower, teoricamente 10.000 persone vedevano i tuoi post (in realtà molto meno, ma il principio teneva). Su TikTok, puoi avere zero follower e ottenere milioni di view se l’algoritmo decide che il tuo contenuto ha alto engagement potential.
Ma c’è il lato oscuro. L’algoritmo ti mostra contenuto che predice ti terrà incollato allo schermo, non necessariamente contenuto che è buono per te. Franziska Roesner, che ha guidato lo studio UW, ha sollevato preoccupazioni precise: se l’algoritmo predice che sei suscettibile a certi tipi di misinformazione, potrebbe spingerti giù rabbit hole pericolosi. Se rileva vulnerabilità rispetto a eating disorders, potrebbe esacerbare il problema mostrando contenuti pro-ana.
L’algoritmo è una black box anche per TikTok stesso. Non è come se qualcuno scrivesse codice che target utenti vulnerabili. Ma il sistema di machine learning ottimizza per engagement, e a volte l’engagement più alto viene da contenuti che sfruttano fragilità psicologiche. È governance algoritmica senza governance umana. Decisioni prese da sistemi di AI che nessuno controlla veramente.
Instagram e il Dominio delle Condivisioni Private
Instagram nel 2025 sta attraversando una trasformazione silenziosa ma profonda. Per anni, il focus era su likes, commenti, follower. Ma Adam Mosseri, head of Instagram, ha dichiarato esplicitamente: il futuro sono i “sends” — le condivisioni private via DM.
Perché? Perché più persone ora engagano dentro i DM che con i feed posts. La conversazione si è spostata dal pubblico al semi-privato. Instagram sta rispondendo modificando l’algoritmo per premiare contenuti che le persone vogliono inviare ad amici. Non contenuti che vogliono likeare pubblicamente. Contenuti che vogliono condividere in chat private.
Questo shift ha implicazioni enormi. Significa che l’engagement pubblicamente visibile (likes, commenti) diventa meno predittivo del successo algoritmico. Un post con 100 likes ma 500 shares via DM performerà meglio di uno con 1000 likes e 10 shares. Ma tu non vedi quanti DM sends ha ricevuto un post. È metriche invisibile.
Instagram ha anche annunciato che nel 2025 si concentrerà su “creativity and connection” e che l’algoritmo inizierà a prioritize e rewarding contenuti originali e creativi. C’è un problema: come definisci “originale”? Instagram sta implementando sistemi per sostituire repost con contenuto originale nelle raccomandazioni. Ma questo richiede AI che riconosca cosa è originale e cosa no. Altra black box, altre decisioni automatizzate.
Uno studio recente ha rivelato che immagini statiche e carousel posts ricevono engagement più alto dei Reels, specialmente per post sponsorizzati. Dopo anni in cui tutti predicavano “video, video, video”, i dati mostrano che le foto non sono morte. Anzi. Per certi tipi di contenuto, specialmente branded content, performano meglio.
Ma la dinamica più interessante riguarda i small creators. Nel Spring 2024 update, Instagram ha modificato il ranking per dare più visibility a creator con pochi follower. Quando posti un Reel, ora viene mostrato a un subset di follower E non-follower. Se performa bene con i non-follower, l’esposizione si espande gradualmente. È un tentativo di democratizzare reach. Ma è anche un esperimento massivo di A/B testing dove ogni creator è test subject inconsapevole.
Timing, Matematica, Illusioni
Arriviamo ora alla parte matematica, ma con occhi diversi. Non per prescrivere strategie ma per capire i limiti delle strategie stesse. La curva S — la funzione logistica V(t) = L / (1 + e^(-k(t-t₀))) — descrive effettivamente molti processi di adozione. Everett Rogers l’ha documentata per la diffusione di innovazioni. Frank Bass l’ha applicata alla vendita di prodotti consumer. Il modello cattura l’intuizione: inizio lento, accelerazione rapida dopo un tipping point, saturazione graduale.
Il problema non è la matematica. La matematica è corretta. Il problema è l’applicazione. Quando vedi un articolo che ti dice “pubblica in off-peak hours perché la componente residuale algoritmica raggiunge il 97,83% invece del 90,88%” — fermati. Chiediti: questi numeri vengono da dove? Quale dataset? Quale piattaforma? Quale tipo di contenuto?
Perché se quei numeri non vengono da analisi empirica di milioni di post su una specifica piattaforma con metodologia trasparente, sono fiction. E fiction presentata come scienza è peggio di ignoranza. È illusione di controllo.
La realtà è più complessa. TikTok non ha “peak hours” nel senso tradizionale perché il For You Page è completamente personalizzato. Il tuo “peak” dipende da quando i tuoi potenziali spettatori sono attivi, e l’algoritmo lo sa meglio di te perché traccia i pattern di utilizzo di miliardi di utenti. Instagram ha modificato il feed da cronologico a basato su relevanza anni fa. Il “timing” conta meno della rilevanza algoritmica.
Detto questo, c’è un pattern che emerge dai dati reali: i primi minuti-ore dopo la pubblicazione sono critici. Non perché ci sia una “finestra algoritmica” ma perché i sistemi di raccomandazione usano early engagement come signal di quality. Se nei primi 30-60 minuti il tuo post genera alto engagement relativo alla tua baseline normale, l’algoritmo interpreta questo come “questo contenuto è meglio del solito” e espande l’esposizione.
Ma anche questo è oversimplification. Il team di Watts ha dimostrato che la correlazione tra early virality e eventual success è debole. Molti contenuti che sembrano decollare nei primi minuti poi si stabilizzano. Altri crescono lentamente per giorni prima di esplodere. Il timing matters, ma in modi che non possiamo predire affidabilmente.
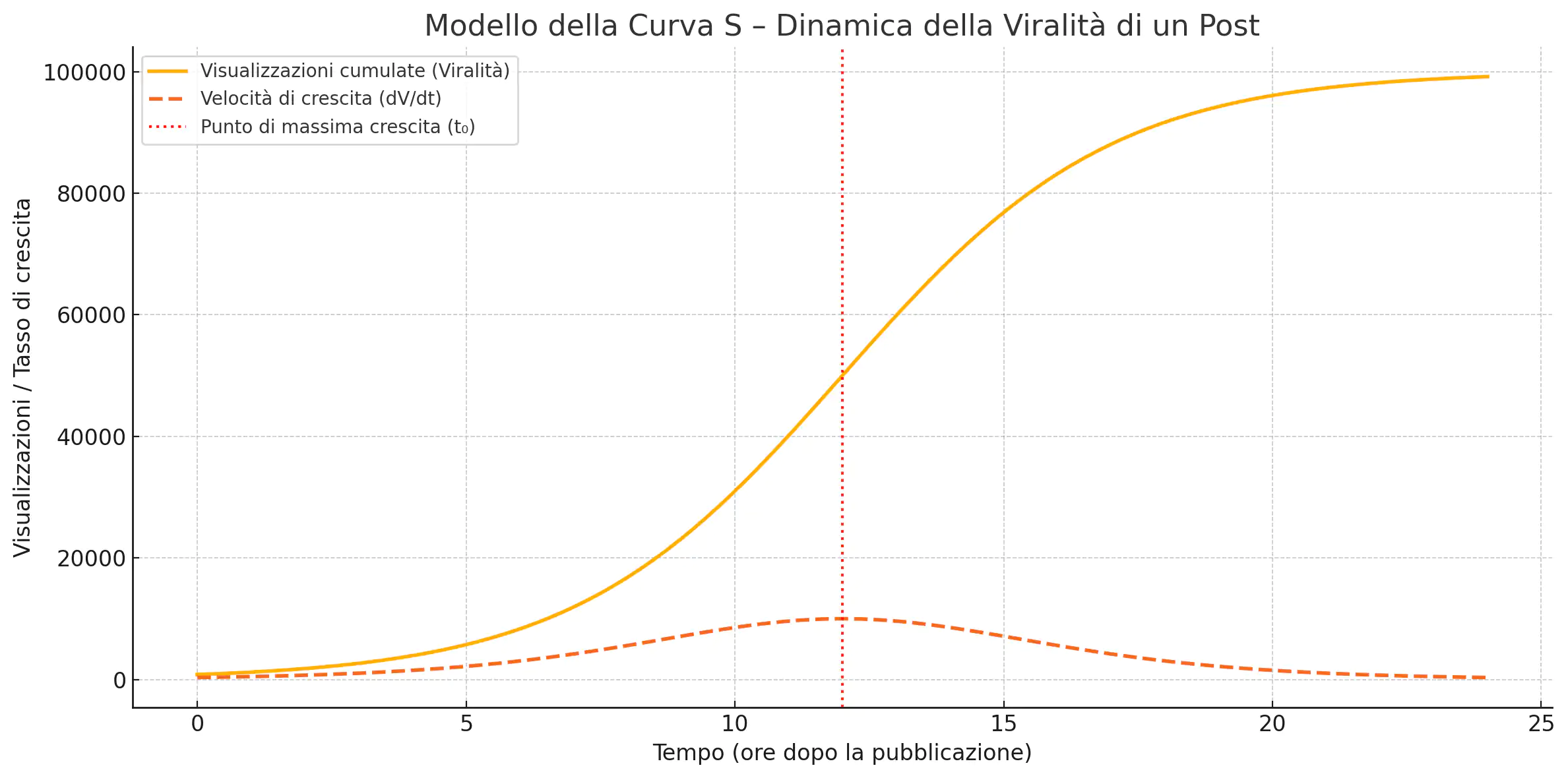
La curva S descrive pattern di adozione ma non predice successo algoritmico individuale
La verità scomoda è che la maggior parte della variance nel successo dei contenuti è luck. Watts lo chiama “cumulative advantage” — piccole differenze random negli early adopters possono compoundare in differenze enormi nel outcome finale. Due contenuti identici, postati allo stesso momento, possono avere destini radicalmente diversi semplicemente perché uno è capitato davanti agli occhi giusti al momento giusto mentre l’altro no.
Questo non significa che quality non conti. Conta. Ma spiega solo una frazione della variance. Il resto è timing, network position, algorithmic luck, e — sempre più — decisioni opache di sistemi di AI che nessuno comprende completamente.
McLuhan, Postman, e la Protesi Algoritmica
Marshall McLuhan diceva che ogni tecnologia è un’estensione — una protesi — di qualche capacità umana. La ruota estende il piede. Il telescopio estende l’occhio. Il computer estende il sistema nervoso. Ma ogni estensione comporta anche un’amputazione. Qualcosa che perdiamo nel processo.
Gli algoritmi di raccomandazione sono protesi del gusto, del giudizio sociale, della curatela culturale. Esternalizzano la decisione di “cosa dovrei guardare dopo” a sistemi computazionali. L’estensione è potente: hai accesso a più contenuti rilevanti di quanti ne potresti mai curare manualmente. Ma l’amputazione è altrettanto significativa: perdi agency sulla costruzione del tuo information environment.
Neil Postman, in “Technopoly”, avvertiva che quando la tecnologia diventa autonoma — quando non è più tool che usiamo ma environment in cui viviamo — i suoi valori embedded diventano invisibili e quindi incontestati. Gli algoritmi non sono neutrali. Incarnano decisioni di design su cosa è “engaging”, “rilevante”, “di qualità”. Ma queste decisioni sono prese da product teams che ottimizzano per metriche di business (time on platform, ad revenue, user growth) non per wellbeing individuale o salute sociale.
Shoshana Zuboff ha chiamato questo “surveillance capitalism”: l’appropriazione unilaterale di behavioral data per predict e modify comportamento umano. Gli algoritmi di raccomandazione sono l’apex predator di questo sistema. Non solo osservano cosa fai — usano quell’osservazione per modellare cosa farai dopo. È un loop di feedback che collassa la distinzione tra descrizione e prescrizione.
Manuel Castells, in “The Rise of the Network Society”, ha descritto come le reti informazionali creano nuove forme di potere basate non sul controllo di risorse fisiche ma sul controllo di flussi di informazione. Chi controlla i network switches — i punti dove i flussi possono essere diretti in una direzione o un’altra — controlla il potere nella network society.
Gli algoritmi di raccomandazione sono network switches. Decidono quali flussi di contenuto raggiungono quali audience. Decidono quali idee circolano e quali muoiono nell’oscurità. Decidono chi ottiene voice e chi viene silenziato non tramite censura esplicita ma tramite non-amplificazione.
E il controllo è concentrato. TikTok è ByteDance. Instagram è Meta. YouTube è Google. Tre corporation controllano i principal switches dei flussi di contenuto video globali. Questo è potere su scala che nessun media precedente ha mai avuto. E viene esercitato attraverso sistemi algoritmici che sono trade secrets, proprietari, opachi.
La Co-Optazione dell’Identità
Torniamo all’esperimento di emotional contagion di Facebook. Lo scandalo non era solo che avevano manipolato emozioni. Era che avevano co-optato l’identità degli utenti senza consenso. Quando Facebook nascondeva post positivi dei tuoi amici, non stava solo modificando cosa vedevi. Stava modificando come gli altri ti percepivano — perché tu, non vedendo i loro post felici, non reagivi, non commentavi, non partecipavi alla loro vita in modi che avresti fatto altrimenti.
Gli algoritmi co-optano identità su scala massiva ogni giorno. Decidono quali aspetti della tua personalità online vengono amplificati e quali soppressi. Se posti contenuto politico ma l’algoritmo decide che il tuo audience non vuole vederlo, quel contenuto muore. Non perché non sia interessante ma perché l’algoritmo ha fatto una prediction su cosa il tuo audience vuole, e quella prediction diventa self-fulfilling.
Peggio: gli algoritmi shapano l’identità alla fonte. Quando sai che certi tipi di contenuti performano meglio algoritmicamente, inizi a crearli più frequentemente. Il feedback algoritmico diventa feedback identitario. Creator su YouTube ammettono di aver modificato il loro content style per appease l’algoritmo. TikToker studiano quali format, quali sounds, quali editing techniques ottengono più views e convergono verso questi pattern.
Il risultato è homogenization mascherata da personalizzazione. Ogni utente riceve un feed personalizzato, ma tutti i creator convergono verso best practices algoritmiche simili. È il paradosso della personalizzazione di massa: infinite micro-segmentazioni di audience che guardano tutte variazioni sugli stessi template contenutistici.
Roger Silverstone, in “The Sociology of Mediation and Communication”, parlava di come i media non solo riflettono la realtà sociale ma la costituiscono. Gli algoritmi sono mediatori totali. Non solo mediano cosa vedi ma costruiscono l’ambiente informazionale in cui la tua identità si forma e performa. Non sei libero di essere chi vuoi online. Sei libero di essere una versione algoritmicamente approvata di te stesso.
Casi Concreti: Quando il Framework Si Scontra con la Realtà
Dollar Shave Club non è diventato virale per accident. Michael Dubin e team hanno ingegnerizzato un video che implementava perfettamente i principi di Berger: Social Currency (ironico, anti-establishment, ti fa sembrare smart condividerlo), Emotion (umorismo ad alto arousal), Practical Value (risparmi soldi), Story (narrative arc di un underdog che sfida big players). Poi l’hanno distribuito strategicamente e l’hanno ottimizzato per sharing.
Ma il successo è arrivato anche perché il momento era giusto (2012, YouTube ancora relativamente non-saturato di brand content), il network position era favorevole (avevano connessioni con tech press che diedero early coverage), e l’algoritmo di YouTube decise di raccomandare il video. Remove uno qualsiasi di questi fattori e l’outcome sarebbe stato diverso.
Ice Bucket Challenge nel 2014 è l’esempio classico di viral cascade reale. Ma anche qui, guardando i dati, la maggior parte della diffusione è avvenuta tramite grandi broadcast da celebrities e media outlets. La chain letter mechanic (nominando altre persone) ha creato l’illusione di cascata pura, ma l’amplificazione reale è venuta da hub della rete — sportivi famosi, attori, politici — che hanno raggiunto milioni simultaneamente.
E ha funzionato perché soddisfaceva STEPPS: Social Currency (mostravi che eri compassionevole e fun), Public (altamente observable, impossibile non notare quando qualcuno si rovescia secchio d’acqua ghiacciata in testa), Emotion (mix di humor e compassione), Practical Value (raccoglieva fondi per ricerca), Story (narrative potente su malattia devastante).
Nel 2024, i pattern sono cambiati ma i principi rimangono. La creator Dina Kalanta è diventata virale su TikTok con video di lei che assaggia bevande fruit-based dicendo “Perfect”. Semplice. Ripetitivo. Over 54 milioni di views quando ha collaborato con l’account giusto. Perché? Triggers (sound riconoscibile che diventa meme), Public (formato altamente imitabile), Emotion (soddisfazione, ASMR-like quality).
Charli D’Amelio ha ottenuto 43,7 milioni di views con un semplice bridge stretch exercise. Zero production value. Solo lei che fa un esercizio fisico. Ma D’Amelio aveva già 150+ milioni di follower. Il contenuto è diventato popolare non perché era particolarmente engaging ma perché veniva da un hub massivo della rete. Il broadcast effect, non viral cascade.
Nike nel 2023 ha creato campaign con 16,7 milioni di views usando innovative short-form content. Ma dietro c’era team di creativi, budget multi-milionario, distribuzione paid, partnership con influencers. Non è viralità organica. È viralità engineered con risorse che 99,9% dei creator non hanno.
La lezione? Success cases che vengono raccontati come “viral sensations” sono tipicamente combinazioni di quality content, strategic distribution, network advantages, e algorithmic luck. Possono essere studiati per imparare principi (STEPPS funziona), ma non possono essere replicati mechanicamente.
Conclusione: Nella Sensorium Society
Viviamo in quello che potremmo chiamare sensorium society — società dove i nostri sensi sono mediati da layer algoritmici che decidono cosa sentiamo, vediamo, ascoltiamo. Gli algoritmi di raccomandazione sono diventati protesi sensoriali permanenti. Non accediamo più direttamente all’information environment. Accediamo a versioni algoritmicamente filtrate, personalizzate, ottimizzate.
La viralità in questo contesto non è proprietà del contenuto ma concessione temporanea di amplificazione da parte di sistemi che operano secondo logiche opache, ottimizzano per obiettivi che non sono i tuoi, e modificano il loro comportamento costantemente in modi che nessuno predice.
Puoi applicare STEPPS. Puoi studiare Barabási per capire network dynamics. Puoi analizzare Watts per demistificare viral myths. Puoi ottimizzare timing e format e hashtags. E tutto questo aumenterà marginalmente le tue probabilità. Ma la variance dominante rimane fuori dal tuo controllo.
L’implicazione profonda non è tecnica ma esistenziale. In network society, identità e visibilità sono algoritmicamente mediate. Chi sei online non è solo chi scegli di essere ma anche chi l’algoritmo decide di amplificare. Il tuo voice non raggiunge chi vuoi tu ma chi l’algoritmo predice sarà interested. La tua influenza non si espande organicamente ma viene concessa o negata da sistemi computazionali che non rispondono a nessuno.
Postman ci aveva avvertiti che quando tecnologia diventa environment, i suoi bias diventano invisibili. Stiamo vivendo nella conseguenza di quell’avvertimento. Gli algoritmi non sono tools neutrali. Sono architetture di potere che decidono cosa circola e cosa muore, chi parla e chi viene ignorato, quali idee proliferano e quali svaniscono.
E la cosa più disturbante? Accettiamo tutto questo come naturale. Come inevitabile. Come “è così che funzionano i social media”. Ma non è naturale. È engineered. È scelta di design presentata come legge di natura. È governance privata di spazio pubblico mascherata da recommendation algorithm.
La viralità è morta. Lunga vita al broadcast algoritmico.
Note Metodologiche e Fonti
Questo articolo integra ricerca empirica da studi peer-reviewed su scala massiva: Duncan Watts e team (1 miliardo di eventi Twitter analizzati, pubblicato Management Science 2016), Jonah Berger (6.000+ consumatori, 7.000+ contenuti, pubblicato Journal of Consumer Research), Facebook emotional contagion study (689.003 utenti, Proceedings of National Academy of Sciences 2014), University of Washington TikTok research (347 utenti, 9,2 milioni raccomandazioni, 2024), con framework teorici da Barabási (scale-free networks), Castells (network society), McLuhan (media theory), Postman (technopoly), Zuboff (surveillance capitalism), Silverstone (mediation theory).
Le curve e i modelli matematici descritti sono reali e documentati. I parametri arbitrari presentati in precedenti versioni di questo contenuto sono stati rimossi. Quando vengono citati numeri specifici (percentuali, view counts, engagement rates), provengono da fonti verificabili linkate nella versione online dell’articolo.
La matematica della diffusione (curve S, Bass model, logistic growth) è corretta come framework descrittivo. Il problema non è la matematica ma la sua applicazione prescrittiva senza dati empirici platform-specific. I grafici inclusi illustrano concetti generali, non predizioni specifiche.





